The comprehensive programme will include national and international contributions as well as contributions from our colleagues in the National Cyberinfrastructure System (NICIS): the South African National Research Network (SANReN) and the Data Intensive Research Initiative of South Africa (DIRISA). The 1st and 5th December will be tutorials and workshops, while the main conference will be 2–4 December. Once again, the South African Development Community (SADC) HPC Collaboration Forum will form part of the conference to discuss the SADC HPC framework and implementation plans.
Our expo zone will showcase solutions by leading technology companies and the student competition battleground where 20 teams from universities across the country will be seeking national honours in the 9th Student Cluster Competition and in the 3rd Student Cyber-Security Competition. We trust you will find an exciting programme and we look forward to meeting our regular and new delegates.
| Morning | Afternoon | Evening | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Sun | Workshops | Workshops | |||||||
| Mon | Opening & Keynote | Breakaways | Breakaways | Vendor Crossfire | Keynote | Banquet | |||
| Tue | Keynotes | Breakaways | Breakaways | Women in HPC BoF | |||||
| Wed | Keynotes | Breakaways | Breakaways | CHPC Users BoF | Keynote | Prize-giving | |||
| Thu | Workshops | Workshops | |||||||
Final programme and venue map now available.
THERE WILL BE NO DISCOUNTED REGISTRATIONS AFTER 28 NOVEMBER 2019. WALK-IN REGISTRATIONS ARE FULL PRICE.
A comprehensive introduction to the CHPC systems for new and current users covering the basics, the PBS Pro scheduler, and practical HPC. This is aimed at users at all levels and will show how to turn your scientific workflow into a CHPC job script for the Lengau cluster.
A comprehensive introduction to the CHPC systems for new and current users covering the basics, the PBS Pro scheduler, and practical HPC. This is aimed at users at all levels and will show how to turn your scientific workflow into a CHPC job script for the Lengau cluster.
A comprehensive introduction to the CHPC systems for new and current users covering the basics, the PBS Pro scheduler, and practical HPC. This is aimed at users at all levels and will show how to turn your scientific workflow into a CHPC job script for the Lengau cluster.
A comprehensive introduction to the CHPC systems for new and current users covering the basics, the PBS Pro scheduler, and practical HPC. This is aimed at users at all levels and will show how to turn your scientific workflow into a CHPC job script for the Lengau cluster.
Generally, a lot of awareness has been created around Digital Transformation/ the Fourth Industrial Revolution (4IR) with various stakeholders electing to focus on matters of interest to them. However, there are known challenges and requirements for the public service to be able to transform digitally. The presentation would talk about challenges/ issues (people/ process/ technology issues) that require interventions/ solutions to achieve a Digitally Transformed public service.
Personalised solutions for healthcare are increasingly recognised as an important approach for treating a variety of conditions that have different outcomes, based on the patient. In the field of computational mechanics, different virtual pipelines have been developed in an effort to improve interventional planning and long-term patient outcomes. One of the major challenges to realising patient-specific treatment tailoring is a mismatch of timeframes. Clinical diagnoses and treatments need to be carried out in as short a timeframe as possible, while traditional CFD codes tend to run over longer time periods.
The use of high performance computing platforms has been beneficial in the development of interventional planning pipelines for cerebral aneurysm thrombosis and congenital heart disease. For aneurysms, it is important to determine what type of clot will form in the aneurysm sac, based on the treatment modality selected. In the case of congenital heart disease, treatments which are selected need to be optimised to ensure that solutions will remain suitable as the child grows to adulthood. This talk will explore the challenges encountered in developing these two pipelines for clinical use.
The advent and evolution of next generation sequencing (NGS) has considerably impacted genomic research, including precision medicine. High-throughput technology currently allows for the generation of billions of short DNA or RNA sequence reads within a matter of hours. This becomes extremely important in the case of genetic disorders where rapid and inexpensive access to a patient’s individual genomic sequence is imperative and enables target variant identification. NGS technologies results in the generation of large data sets which require extensive bioinformatic and computational resources. Computational life sciences therefore relies on the implementation of well-structured data analysis pipelines as well as high-performance computing (HPC) for large-scale applications. Here, we report the sequencing of the first six whole human genomes in South Africa and the processing of the data in collaboration with the Centre for High Performance Computing (CHPC). Efficient parallel and distributed implementations of common time-consuming NGS algorithms on modern computational infrastructures are imperative. The latter becomes pivotal as NGS will continue to transcend from research labs to clinical applications in the near future.
ABSTRACT:
The future of spintronics based on 2D-materials is dependent on the effectiveness of the injection of pure spin current into a tunnel barrier region. Here, first principles calculations are used to show that the efficiency of the spin-filtering across the semiconducting barriers of monolayer hBN is mainly limited by the dynamical response of tunneling electrons to the applied axial field. By projecting the effective electric field gradient densities and magnetic shielding constants across constitutive atomic layers in the scatter region of spin-filter tunnel junctions, an unusual site-dependent spin response is unraveled at the Fe/hBN and hBN/metal heterobilayer interfaces. Since the ground-state energy has no lower bound in extended electric fields, our analyses of the dependence of the Fermi surface topology on applied electric fields show the emergence of a frustrated electronic order. This exotic electronic phase is characterized by electric-field induced spin-flip relative to the ferromagnetic ground state, and observable as field-tunable perpendicular magnetic anisotropy.
HPC Content:
All the calculations were performed in parallel using version 6.4.1` of the Quantum ESPRESSO suite. Due to poor code scalability, all the computations were carried out on the 'SMP que' using 1 Node of 24 CPU cores. No net gain in computing speed was observed when more nodes were used on larger system sizes. In fact, the speed of the computations significantly reduced to > 6 CPU hours per scf-cycle when the same jobs were running on the 'Normal que' at 10 Nodes at double the system-size. The main computational challenge lies in solving the associated Poisson’s equation for atoms in the presence of the compensating potential due to externally-applied fields under gauge-corrections, in a more efficient manner. For fully-converged field-dependent computations, an average duration per task was timed at 2d 0h19m (CPU time) and 2d 0h40m (WALL time). This is still too 'slow' for scientific computing jobs executed on a supercomputer.
High-performance computing (HPC) applications generate massive amounts of data. However, the performance improvement of disk-based storage systems has been much slower than that of memory, creating a significant I/O performance gap. To reduce the performance gap, storage subsystems are under extensive changes, adopting new technologies and adding more layers into the memory/storage hierarchy. With a deeper memory hierarchy, the data movement complexity of memory systems is increased significantly, making it harder to utilize the potential of the deep memory-storage hierarchy (DMSH) architecture. In this talk, we present the development of Hermes, an intelligent, multi-tiered, dynamic, and distributed I/O caching system that utilizes DMSH to significantly accelerate I/O performance. Hermes is a US NSF supported large software development project. It extends HPC I/O stacks to integrated memory and parallel I/O systems, extends the widely used Hierarchical Data Format (HDF) and HDF5 library to achieve application-aware optimization in a DMSH environment, and enhances caching systems to support vertical and horizontal non-inclusive caching in a distributed parallel I/O environment. We will introduce the Hermes’ design and implementation; discuss its uniqueness and challenges; and present some initial implementation results.
The MeerKAT archive was made accessible from the internet earlier this year.
This allow researchers from across the world to pull data from the MeerKAT archive.
In this talk I'll describe the MeerKAT storage system that consists out of several petabytes of observations backed by a Ceph distributed storage system. The use of Ceph at SARAO and the infrastructure around the archive will be described. There after the data access methods from the internet and from partner institutes like the CHPC will be presented.
Accelerating discovery in computational science and high performance computing environments requires compute, network and storage to keep pace with technological innovations. Within a single organization, interdepartmental and multi-site sharing of assets has become more and more crucial to success. Furthermore, as the growth of data is constantly expanding, storage workflows are exceeding the capabilities of the traditional filesystem. For most organizations, facing the challenge of managing terabytes, petabytes and even exabytes of archive data for the first time can force the redesign of their entire storage strategy and infrastructure. Increasing scale, level of collaboration and diversity of workflows are driving users toward a new model for data storage.
In the past, data storage usage was defined by the technology leveraged to protect data using a pyramid structure, with the top of the pyramid designated for SSD to store ‘hot’ data,’ SATA HDDs used to store ‘warm’ data and tape used for the bottom of the pyramid to archive ‘cold’ data. Today, modern data centers have moved to a new two-tier storage architecture that replaces the aging pyramid model. The new two-tier paradigm focuses on the actual usage of data, rather than the technology on which it resides. The new two-tier paradigm combines a project tier that is file-based and a second or perpetual tier which is object based. The object based perpetual tier includes multiple storage media types, multi-site replication (sharing), cloud, and data management workflows. Data moves seamlessly between the two tiers as data is manipulated, analyzed, shared and protected – essentially creating yin and yang between the two storage tiers. Solutions designed to natively use the Perpetual Tier empower organizations to fully leverage their primary storage investments by reducing the overall strain on the Primary Tier, while at the same time, enabling data centers to realize numerous benefits of the Perpetual Tier that only increase as the amount of storage to manage increases.
The next logical question is how to manage data between the two tiers while maintaining user access and lowering overall administration burdens. Join us for a deeper look into the nuances of the two-tier system and data management between them. We will cover storage management software options; cloud vs. on-premise decisions; and using object storage to expand data access and create a highly effective storage architecture to break through data lifecycle management barriers
Prof Mahmoud Soliman (http://soliman.ukzn.ac.za/) will provide a presentation that highlights the various research scopes and outcomes of research that is being conducted in his research group at UKZN over the last 8 years with more emphasis on the applications of computational simulations and the contribution of CHPC in drug design and discovery as well as capacity development. A few selected research topics will be presented such as: the irony of chirality; covalent drug inhibition; does drug size matter; and other topics.
The parallel cluster at the CHPC is used to provide speed-up on three fronts in the Computational Fluid Dynamics (CFD) simulations discussed. The first is for optimization of the parameterized geometry of a swirling jet impingement solar thermal receiver where many runs of fairly large Large Eddy Simulation CFD models are required. The second problem that benefits from the massively parallel approach, is that of a transient simulation of the atmospheric boundary layer turbulent flow field around a heliostat with a very small time step, requiring many time steps for a meaningful time series. This simulation is required to determine peak loads and perform the fluid-structure interaction of such a solar collector. The last type is for large models of wind flow over Marion island containing close to hundred million computational cells. These models are used to predict wind patterns that affect plant and bird life, especially as influenced by continued climate change.
Room Temperature Ionic Liquids (RTILs), which are broadly defined as salts that are liquid below 100 °C, offer an alternative to typical organic solvents. Favourable properties, such as high thermal stability, large melting range, low vapour pressure (and consequently low flammability) and miscibility with both polar and nonpolar compounds, provide the motivation for these systems to become next-generation solvents for synthesis, catalysis and separation technologies. Since all ILs consist of both a cation and anion, interchange between existing and novel ions can deliver a vast set of new solvent systems, much quicker than derivatisation of regular, molecular systems. Consequently, the millions of potential systems for exploration make property prediction of novel ILs an exciting research opportunity. Coupled with the global demand to reduce waste and develop processes within the principles of sustainable and green chemistry, there is increasing interest in moving away from conventional solvent systems.
To speed up rational design methodologies and avoid costly synthetic routes, cost-effective alternatives to experimental screening of potential new ILs for favourable physical and mechanical properties are needed. The estimation of thermodynamic properties is an essential component of this task and the application of high-performance computing is central to achieving this. Estimation methods can come in various forms but can be divided into three broad categories: (1) molecular/atomistic simulation and computation, (2) empirical modelling (e.g. equations of state) or (3) quantitative structure property relationships, driven by machine learning approaches. The first requires a classical or quantum mechanical description of molecules and a theoretical framework (such as statistical mechanics) to derive macroscopic properties from these; the second is immersed in classical thermodynamics and exploits the relationships between state variables; the last finds patterns in data and can build linear or nonlinear functions of user-defined features to express physical properties without the need for direct, prior knowledge of these. Each comes with its own strengths and weaknesses in terms of resources needed (empirical information and computational cost), domain of applicability, accuracy and ease-of-use.
In this presentation, the prediction power of molecular simulation and machine learning methods as applied to ILs is put to the test. The constant pressure heat capacity is chosen as the target—this property expresses the response of a system’s energy to a temperature change and can be both quantified theoretically and measured experimentally with reasonable ease. A test set of five structurally diverse ionic liquids have been picked and their temperature dependent heat capacities calculated using classical molecular dynamics (MD) simulations with various force field implementations as well as a selection of machine learning algorithms. In addition to discussing the accuracy, the strengths and weaknesses of the difference approaches are also compared.
MD simulations, of systems consisting of 10k to 20k atoms, were run using the AMBER code, which has been implemented on both GPU and CPU architectures. The former is highly efficient and speedups in excess of 20x can be obtained (> 500 ns/day). The CPU code runs in parallel using an MPI implementation that scales well up to 64 processors (system size dependent). The Scikit-learn Python framework was used for machine learning model development with the Keras API and TensorFlow as backend for the artificial neural network models. In addition to built-in support for multithreading, where applicable, embarrassingly parallel steps in model training and validation were optimized using the mpi4py module.
For decades, Praziquantel has been the undisputed drug of choice against schistosomiasis; a disease that affects more than 200 million people in over 78 countries and responsible for over 280 000 lives lost per annum, predominantly in sub-Saharan Africa. Rising concerns have been raised due to the unknown mechanism of action of the drug and unavoidable reports of the emergence of drug resistant strains. Moreover, current apprehension has been reinforced by the total dependence on a single drug for treatment. Therefore, the search for novel and effective anti-schistosomal drugs become imperative. This study made use of bioinformatics tools to determine the binding properties of a selective range of polyphenols docked onto the Universal stress G4LZI3 protein, a recently identified ‘lead’ molecule in the design of alternative treatment drug against schistosomiasis. Schistosomes have over several years, evolved mechanisms that include the presence of USPs, to counter biotic and abiotic stress. Up-regulation of the G4LZI3 protein throughout the multifaceted developmental cycle of the schistosome worm sparks interest in this protein, whose function is currently unknown. Ten polyphenols were docked onto the G4LZI3 protein; the best five complexes were selected for post-molecular dynamics analyses and binding free energy calculations. The strongest binding interactions were observed between the G4LZI3 protein with curcumin and catechin respectively. The major interacting residues conserved in all the complexes provides basis for further structure-based drug design of new compounds, with enhanced inhibitory potency and toxicity against G4LZI3. This study suggests an alternative approach for the development of anti-schistosomal drugs using natural compounds.
The rise of AI/ML in HPC applications is also driving the need for suitable storage abstractions such as the key-value (KV) stores. These abstractions pose new challenges for the HPC I/O stack. Enterprise KV stores are not well suited for HPC applications, and entail customization and cumbersome end-to-end KV design to extract the applications needs. To this end, I will present BESPOKV, an adaptive, extensible, and scale-out KV store framework. BESPOKV decouples the KV store design into the control plane for distributed management and the data plane for local data store. BESPOKV takes as input a single-server KV store, called a datalet, and transparently enables a scalable and fault-tolerant distributed KV store service. The resulting distributed stores are also adaptive to consistency or topology requirement changes and can be easily extended for new types of services. I’ll show that BESPOKV-enabled distributed KV stores scale horizontally to a large number of nodes, and performs comparably and sometimes better than the state-of-the-art systems.
Portable, Extensible Toolkit for Scientific Computation (PETSc) is a suite of
data structures and routines for the scalable (parallel) solution of scientific applications. Due to its solid mathematical grounding, careful software design, and most importantly, evolution resulting from the usage of many users in various application areas, PETSc is enabling engineers and scientists to solve large scale problems, with previously unreachable resolution, in areas as diverse as groundwater contamination, cardiology, fusion, nuclear energy, astro-physics, and climate change.
As a PETSc developer, I will give an overview of the PETSc, and briefly introduce its basic use in algorithmic research, numerical production simulation and parallel performance evaluation. As an example, I will present our recent simulation of the U.S. river systems on extreme-scale computers.
Memory and storage read and write costs can lead to a significant loss of time and energy in current HPC systems. Byte-addressable non-volatile memory (NVM) could provide considerable improvements in both time and energy requirements over conventional DRAM memory. Using Optane DCPMM, Intel's new byte-addressable and persistent memory, the NEXTGenIO project investigated the performance of NVRAM by designing, building and testing a bespoke prototype NVM system. The main goal of the project was to explore the potential of NVRAM in overcoming performance bottlenecks in I/O and main memory, which are considered significant barriers to Exascale computing.
In this talk we will give a brief overview of the NEXTGenIO system (192GB DRAM and 3TB of NVM per dual socket node), and the various NVRAM usage modes. The results from a number of investigative test cases run on the NEXTGenIO prototype system will be presented. In particular we will discuss I/O performance, run-time, and energy consumption for applications with large I/O demands, such as OpenFOAM and CASTEP. Comparison of the results from NVRAM and DRAM shows that NVRAM can indeed provide significant improvement in both performance and energy consumption.
Science and education are increasingly becoming global endeavors. Scientists collaborate internationally and questionnaires indicate that scientists today are more likely to collaborate with partners outside their home institutions than with local research fellows. Students no longer need to physically be on campus to take classes, as they follow courses remotely and can even take a degree at foreign university without leaving home. Furthermore, there is a growing number of international research infrastructures, some centralized and some highly distributed, in all areas of science. The construction of those infrastructures is partly driven by financial necessity, but also from a need to bring together the necessary competences. Furthermore, the paradigms of Open Science and Citizen Science foster foster an environment of sharing and inclusion. Collaboration is no longer just a matter of scientist visiting for weeks and months.
For these reasons, access to facilities, research infrastructures, and data must be global, universal, fine-grained, and instant. As an eInfrastructure provider, R&E Network organizations are one of the fundamental building blocks supporting today’s global science, and just as scientific activities are becoming more and more global, we need to think global. With the network, we already see this happening, where leading NRENs, such as the South African NREN, participate in the Global Network Advancement Group, that works on the intercontinental aspects of the (GREN) Global R&E Network. Moreover, network services such as eduroam, eduGAIN, and eduVPN take a truly global approach. The infrastructure needed to support Open Science and Citizen Science drives us to break down silos between storage, compute, and network infrastructures. We need to think about it in its entirety. The same goes for some of the large international research infrastructures, where storage, compute, and the network become an integral part of the science instrument. In this talk, I will present my views on the role of R&E Networks as enablers for science and education, with an outset on what I see happening in the European Nordics, at a European level, and globally.
This talk discusses two emerging trends in computing (i.e., the convergence of data generation and analytics, and the emergence of edge computing) and how these trends can impact heterogeneous applications. Next-generation supercomputers, with their extremely heterogeneous resources and dramatically higher performance than current systems, will generate more data than we need or, even, can handle. At the same time, more and more data is generated at the “edge,” requiring computing and storage to move closer and closer to data sources. The coordination of data generation and analysis across the spectrum of heterogeneous systems including supercomputers, cloud computing, and edge computing adds additional layers of heterogeneity to applications’ workflows. More importantly, the coordination can neither rely on manual, centralized approaches as it is predominately done today in HPC nor exclusively be delegated to be just a problem for commercial Clouds. This talk presents case studies of heterogenous applications in precision medicine and precision farming that expand scientist workflows beyond the supercomputing center and shed our reliance on large-scale simulations exclusively, for the sake of scientific discovery.
The work illustrates the integration of basic and applied chemistry in the development and application of selective materials for application in desulfurization and denitrogenation of fuel as well as in separation of precious metals. The fuel chemistry study is important from the point of view of the need to drive towards a zero sulfur fuel as mandated by environmental protection agencies in many countries around the world.1 Challenges exist with the current hydrodesulfurization and hydrodenitrogenation processes that are being applied in refineries as they fail to achieve the requisite fuel standards. The second application of functional materials is in separation of important metals. The demand for precious metals is driven by their important applications, and the development of better separating reagents/materials has become important given that the quality of ores is decreasing, and better recovery rates of the metals from secondary sources (such as electronic boards and catalytic converters) will be required in future. This necessitates improvement of the current chemistry in order to process the new feeds.
Experimental and theoretical studies were carried out during the development of the functional chemistry for recognition of target metals and organic compounds. The selective chemistry towards fuel contaminants such as organosulfur and organonitrogen compounds has been developed, and the results are promising as the best material (polymenzimidazole nanofibers) achieve sulfur removal of less than 2 ppm.2 A process involving conversion of sulfur compounds to organosulfones compounds3 has been developed followed by removal of the polar sulfones using selective materials.2 The approach for materials development for metal ions, such as platinum group metals (PGMs), follows the development of reagents that are specific for metal ion chlorido complexes of interest. The innovation of the aforesaid reagents undoubtedly requires a design strategy that considers both the electronic and stereochemical requirements of the target anion. Through a combination of molecular modelling techniques and experimental techniques, we have been able to derive factors that lead to successful separations. Cations as anion receptors specific for [IrCl6]2- and [PtCl6]2⁻ will be presented as well as selective chemistry for orgnosulfur and organonitrogen compounds in fuel. Binding energies and other thermodynamic parameters have been calculated in silico to explain the chemistry involved.
References:
1. Barbara, P.; Rufino, M.N.; Campos-Martin, J.M.; Fierro, J.L.G.; Catal. Sci. Technol., 2011, 1, 23-42.
2. Ogunlaja, A.S.; du Sautoy, C.; Torto, N.; Tshentu, Z.R.; Talanta, 2014, 126, 61–72.
3. Ogunlaja, A.S.; Chidawanyika, W.; Antunes, E.; Fernandes, M.A.; Nyokong, T.; Torto, N.; Tshentu, Z.R.; Dalton Trans, 2012, 41, 13908-13918.
The increasing computational power of HPC systems fosters the
development of complex numerical simulations of phenomena in different
domains, such as medicine [1], Oil & Gas [2] and many other fields [3,4,5].
In such applications, a huge amount of data in the form of multidimensional
arrays is produced and need to be analyzed and visualized enabling
researchers to gain insights about the phenomena being studied.
Scientists also generate huge multidimensional arrays through
environmental observations, measurements of physical conditions and
other types of sensors. For instance, satellite data for Earth's weather,
oceans, atmosphere and land [6] are kept in the form of multidimensional
arrays in scientific file formats. Data collected by sensors in physics
experiments, such as the ones conducted in the photon studies by SLAC
National Accelerator Laboratory [7], are also represented and processed in
the form of multidimensional arrays.
Machine learning is another context in which multidimensional arrays are
present. They are the basic input format for the heavily optimized linear
algebra algorithms implemented in deep learning frameworks, such as:
TensorFlow, Keras and Torch. Deep Learning algorithms were able to
achieve superhuman performance for image recognition problems in the
past few years [8], and they are among the most promising alternative for
tackling difficult problems in Natural Language Processing, Image and
Video Recognition, Medical Image Analysis, Recommendation Systems
and many others. Thus, managing these large arrays in the context of deep
learning is a very important task.
The traditional approach for managing data in multidimensional arrays in
scientific experiments is to store them using file formats, such as netCDF
and HDF5. The use of file formats, and not a database management
systems (DBMS), in storing scientific data has been the traditional choice
due to the fact that DBMSs are considered inadequate for scientific data
management. Even specialized scientific data management systems, such
as SciDB [10], are not very well accepted for a myriad of reasons listed in
● the impedance mismatch problem [12,13], that makes the process of
ingesting data into a DBMS very slow.
● the inability to directly access data from visualization tools like
Paraview Catalyst [14] and indexing facilities like FastQuery [13].
● the Inability to directly access data from custom code, which is
necessary for domain specific optimized data analysis.
However, by completely dismissing DBMSs, some nice features also
become unavailable. Including the access for out-the-box parallel
declarative data processing with the usage of query languages and query
optimization, and management of dense and sparse matrices. In this talk,
we will present SAVIME, a Database Management System for Simulation
Analysis and Visualization in-Memory. SAVIME implements a
multi-dimensional array data model and a functional query language. The
system is extensible to support data analytics requirements of numerical
simulation applications.
References
[1] Pablo J. Blanco, M. R. Pivello, S. A. Urquiza, and Raúl A. Feijóo. 2009.
On the potentialities of 3D-1D coupled models in hemodynamics
simulations.Journal of Biomechanics 42, 7 (2009), 919–930.
[2] Cong Tan et al. 2017. CFD Analysis of Gas Diffusion and Ventilation
Protection in Municipal Pipe Tunnel. In Proceedings of the 2017
International Conference on Data Mining, Communications and Information
Technology (DMCIT ’17). ACM, New York, NY, USA, Article 28, 6 pages.
Https: //doi.org/10.1145/3089871.3089904
[3] Igor Adamovich et al. 2015. Kinetic mechanism of molecular energy
transfer and chemical reactions in low-temperature air-fuel plasmas.
Philosophical transactions. Series A, Mathematical, physical, and
engineering sciences 373 (08 2015).
https://doi.org/10.1098/rsta.2014.0336
[4] Mollona, Edoardo, Computer simulation in social sciences, Journal of
Management & Governance, May, 2008, N(2) V(12).
[5] Mitsuo Yokokawa, Ken’ichi Itakura, Atsuya Uno, Takashi Ishihara, and
Yukio Kaneda. 2002. 16.4Tflopss Direct Numerical Simulation of
Turbulence by a Fourier Spectral Method on the Earth Simulator. In
Proceedings of the 2002 ACM/IEEE Conference on Supercomputing (SC
’02). IEEE Computer Society Press, Los Alamitos, CA, USA, 1–17.
http://dl.acm.org/citation.cfm?id=762761.762808 .
[6] R. Ullman and M. Denning. 2012. HDF5 for NPP sensor and
environmental data records. In 2012 IEEE International Geoscience and
Remote Sensing Symposium. 1100–110
[7] Jack Becla, Daniel Wang, and Kian-Tat lim. 2011. Using SciDB to
Support Photon Science Data Analysis. (01 2011).
[8] Dan Ciresan, Alessandro Giusti, Luca M. Gambardella, and Jürgen
Schmidhuber. 2012. Deep Neural Networks Segment Neuronal
Membranes in Electron Microscopy Images. In Advances in Neural
Information Processing Systems 25 , F. Pereira, C. J. C. Burges, L. Bottou,
and K. Q. Weinberger (Eds.). Curran Associates, Inc., 2843–2851.
[9] Z Zhao. 2014. Automatic library tracking database at NERSC. (2014).
https://www.nersc.gov/assets/altdatNERSC.pdf, J. ACM, Vol. 37, No. 4,
Article 111. Publication date: August 2019.
[10] Paradigm4. 2019. SciDB. http://www.paradigm4.com/ [Online;
accessed 01-sep-2019].
[11] Haoyuan Xing, Sofoklis Floratos, Spyros Blanas, Suren Byna, Prabhat,
Kesheng Wu, and Paul Brown. 2017. ArrayBridge: Interweaving declarative
array processing with high-performance computing. arXiv e-prints , Article
arXiv:1702.08327 (Feb 2017).
[12] Spyros Blanas, Kesheng Wu, Surendra Byna, Bin Dong, and Arie
Shoshani. 2014. Parallel Data Analysis Directly on Scientific File Formats.
In Proceedings of the 2014 ACM SIGMOD International Conference on
Management of Data (SIGMOD ’14) . ACM, New York, NY, USA, 385–396.
[13] Luke Gosink, John Shalf, Kurt Stockinger, Kesheng Wu, and Wes
Bethel. 2006. HDF5-FastQuery: Accelerating Complex Queries on HDF
Datasets Using Fast Bitmap Indices. In Proceedings of the
18thInternational Conference on Scientific and Statistical Database
Management (SSDBM ’06). IEEE Computer Society, Washington, DC,
USA, 149–158
[14] Utkarsh Ayachit, Andrew Bauer, Berk Geveci, Patrick O’Leary,
Kenneth Moreland, Nathan Fabian,and Jeffrey Mauldin. 2015. ParaView
Catalyst: Enabling In Situ Data Analysis and Visualization. In Proceedings
of the First Workshop on In Situ Infrastructures for Enabling Extreme-Scale
Analysis and Visualization (ISAV2015) . ACM, New York, NY, USA, 25–29
Direct-current (DC) arc furnaces account for a significant proportion of installed pyrometallurgical capacity worldwide. Their applications include steel recycling as well as smelting of various materials such as ferrochromium, ferronickel, ilmenite, and others. In order to provide power to such furnaces, alternating current from the grid or other generation sources must be converted into DC by rectification. At industrial scales the rectifier unit is often the single largest capital cost item, and any errors in its specification can result in the entire plant operating inefficiently (or not at all).
In this presentation, computational plasma arc models developed in OpenFOAM® are coupled with circuit simulations of solid-state furnace rectifiers in order to gain insight into the complex interactions between the rectifier’s design parameters and the behaviour of the arc. Such approaches provide a first step toward true virtual prototyping and digital twin modelling for the electrical design and optimisation of DC arc furnaces.
High performance computing is a critical enabling tool in such studies, and various aspects of this – including solver performance scaling analysis, software automation, and use of methodologies from other HPC fields – will be touched on during the presentation.
The South African Weather Service has recently embarked on a business case to address its computational needs. Part of this was to identify the most suitable convective scale Numerical Weather Prediction (NWP) model for the Southern African region. The Unified model (UM), the main model run by SAWS for operational purposes, the Weather Research and Forecasting (WRF) Model and the Consortium for Small-scale Modeling (COSMO) model were used for the study. A number of weather parameters were selected for the study, and results generally showed that the three models are comparable. However, with much model development taking place around the world, the COSMO will soon be replaced by the Icosahedral Non-hydrostatic (ICON) model. It, therefore, makes sense to conduct the same study for the ICON as for the COSMO in order to investigate whether the new model is an improvement of the former one. Simulations for both the COSMO and ICON are run on the CHPC.
We investigate the parallelisation and performance analyses of search and planning algorithms for artificial intelligence, machine learning, and software verification. These applications involve the exploration of large state spaces, which requires at its core a combinatorial search algorithm. Much of our work, therefore, focuses on evaluating and improving the scalability of algorithms used in all these tasks.
In recent work we have implemented various parallel and distributed MCTS algorithms with different enhancement strategies for artificial intelligence, tested them for scalability, and compared the performance of these approaches on the same domain and the same hardware infrastructure. We make use of the CHPC's large queue to determine scalability up to 128 12-core compute nodes with 32GB RAM each---values that are in line with previous publications and distributed search implementations. We wrote our application code in Java, using an actor model framework (Akka) to simplify concurrency and distributed computing. We make limited use of MPI---more specifically, just mpirun---in order to easily launch our application on the available nodes using the PBS nodefile.
This talk will provide an overview of our research and the problems we investigate, as well as a discussion of recent results.
Machine Learning methodologies and tools have delivered new approaches to scientific computing ranging from new approximation methods to solve differential equations to leveraging advantages of ML hardware over traditional HPC hardware. It is not unlikely that such approaches will be helpful to computational problems that have seen little progress for decades. We will discuss a few examples, and discuss key themes in carrying this forward.
Two of the typical points of interest with elevation data, or Geographic Information Systems
(GIS) data in general, are storage and query costs. The former is typically addressed by
integrating standard compression schemes into already existing storage mechanisms, such
as GZIP in HDF5. Space-Filling Curves (SFCs) have already been used to reduce access
time for spatial operations on point and polygon data. In this research, we evaluate the effect
of using SFCs as a pre-processing step for standard compression schemes on elevation
data. We break up common compression tools into their base algorithms and identify
canonical SFCs from the literature (for example, the Hilbert curve).
We use 1-arcsecond resolution elevation maps from the Shuttle Radio Topographic Mission
(SRTM) as the comparative data-set upon which we apply all combinations of SFCs and
compression schemes. The SFCs, in most cases, neither significantly improve nor worsen
compression ratios when compared to non-preprocessed results. However, we show that
certain pre-processing steps improve the compression performance of otherwise ineffective
compression techniques. This research shows the potential for future work on compression
schemes which allow for in-place search and modifications without the loss of compression
performance. Another application is to apply these techniques to astronomical data from the
Square-Kilometre Array, a major scientific and engineering project in South Africa, for which
some preliminary results have been attained.
E-learning has been adopted by many institutions as a means by which to foster an effective teaching and learning environment. Namibian institutions of higher learning have not been left behind and are also using e-learning systems. Use of e-learning brings about many benefits like that of students being able to access learning material anywhere and anytime but implementation of e-learning has its own drawbacks of which cloud computing could be the answer. Furthermore, higher learning institutions run their own IT systems and buy their own IT infrastructure which has implications on the overall institutions’ budgets. Data on issues with overall IT operations not just for e-learning systems was obtained from a case site at one of the Namibian institutions of higher learning. The study showed that the institutions’ IT systems have problems that cloud computing could be able to solve.
Keywords: Cloud computing, e-learning, education, downtime
he BRICS Network University (BRICS NU) is a network of 60 universities, 12 each from the five BRICS countries. The BRICS NU is aimed at developing partnerships and exchange programmes in six thematic areas (ITGs) determined by the BRICS Ministries responsible for education. This project forms part of the University Capacity Development Programme (UCDP), an umbrella imitative developed and implemented by the South African Department of Higher Education and Training to build capacity in South African universities in three key areas: student success, staff development and programme/curriculum development. The BRICS NU ITG on Computer Science and Information Security (CSIS) representatives from the BRICS countries, agreed that CSIS ITG will focus on developing a BRICS Masters programme on ìCybersecurity: Software and Data Security. The presentation will include the proposed content, development and implementation plan of the BRICS Masters Programme.
Moving masses of data is a challenge. It can be slow and frustrating to transfer vast quantities of data from the many places it can be stored or generated over general-purpose computer networks.
When scientists attempt to run data intensive applications over campus networks, it often results in slow transfers - in many cases poor enough that the science mission is significantly impacted. In the worst case, this means either not getting the data, getting it too late or resorting to alternative inefficient measures such as shipping disks around.
SANReN would like to provide an update on the Data Transfer Pilot service that is available for the South African Research and Education community, to assist them to move their data locally and internationally. This session will also provide Data Transfer updates within the National Integrated Cyber Infrastructure System (NICIS).
Equity, diversity and inclusion seem to be the magic words of the 21st Century. We’ve all been told they are important, but for many, it is nice-to-have but difficult-to-implement. As there is an increasing shortage of highly skilled technology specialists and an increasingly large array of applications, it has never been more important to implement workable equity, diversity and inclusion practices to ensure that we can attract and retain talent
This session will discuss the benefits of diversity and what we all need to be doing to ensure our community benefits. Discussions will include the work being carried out by Women in High Performance Computing to diversify the international supercomputing community and what the African HPC community can learn from this.
MeerKAT, one of the world’s most powerful radio telescopes in operation today, is producing science-ready data into the now public-facing archive at a steady rate. In this talk, we will assess the performance of off-the-shelf tools for post-processing and imaging MeerKAT data on Lengau.
In understanding and predicting a changing global climate system, the representation of ocean-biogeochemistry processes in the Southern Ocean is particularly important because of the key role it plays in global carbon-climate feedbacks. To date, Earth System Models (ESMs) do not adequately resolve important ocean dynamics (e.g., mesoscale processes), features that are critical in Southern Ocean heat and CO2 fluxes and storage. Therefore high resolution ocean biogeochemical models provide essential constraints to the medium resolution (100km) global ESMs.
The South African ESM, VrESM, comprises of globally coupled atmosphere, ocean, ice, land-surface, atmospheric-chemistry, and ocean-biogeochemistry models. Building and running the ESM is therefore a huge task: both scientifically and computationally. Several numerical models, each discretized on a global grid need to be integrated in space and time, while additionally passing information to each other. As part of a multi-institution and multi-year goal of building South Africa’s first Earth System Model, which will be run at the CHPC, we have been developing the ocean-biogeochemistry component of the VrESM (PISCES-SOCCO). BIOPERIANT12 is a critical platform in this development.
We present the NEMO v3.4 regional model configuration BIOPERIANT12, our most computationally-challenging model to date and run on CHPC’s Lengau cluster. BIOPERIANT12 simulates ocean, ice, biogeochemistry of the circumpolar Southern Ocean (south of 30°S) from 1989 to 2009, prescribed by ERA-interim atmospheric forcing. BIOPERIANT12 is high resolution at a mesoscale-resolving 8 km in the horizontal and in the vertical: ranges from 6 m resolution at the surface to 250 m at the ocean bottom over 46 vertical levels.
In addition to the technical aspect of developing the PISCES-SOCCO source code for VrESM, we have to configure VrESM for an improved representation of the Southern Ocean. BIOPERIANT12, thus serves in multiple ways: (1) as a comparison for ocean biogeochemistry in the ESM, (2) as a large test case for ocean-biogeochemical evaluation metrics for the ESM, (3) as an experimental platform for understanding processes which influence atmosphere-ocean carbon exchange in the Southern Ocean, which additionally helps improve the ESM. We discuss PISCES-SOCCO development progress as well as the building and evaluation of BIOPERIANT12.
Technological development and the internet of things (IoT) increased the data assimilation sources in meteorology through satellites, sensors, weather stations, solar panels, cell phones, traffic lights, to name a few whose number grows daily. This begins to build an ideal scenario for Artificial Intelligence where the demand for data is high. This combined information generates spatio-temporal maps of temperature, rainfall, air movement, etc., with high precision in regions with larger data sources. Applying AI techniques in conjunction with a physical understanding of the environment can substantially improve prediction skill for multiple types of high-impact weather events.
In 2017, the American Meteorological Society (AMS) published a paper [1] with a broad summary indicating how modern AI techniques are helping to improve insights and make decisions in weather prediction. Among the most used techniques are Support Vector Machines (SVM), regression trees, k-means for radar image segmentation and traditional neural networks (ANN). These techniques lack temporal and spatio-temporal analysis, typical of meteorological phenomena. Today, most of the temporal analysis done on meteorological data is through statistical algorithms, such as autoregressive methods. However, the AMS recognizes that the novel Deep Learning techniques could soon be the cause of new improvements and says, “In the future, convolutional neural networks operating in a deep learning framework may reduce the need for feature engineering even further” .
Complementarily, recurrent neural networks, designed for analysis of natural language processing, are known by their results in numerical problems like temperature prediction, among others. In order to improve the temporary forecasts of spatio-temporal phenomena, such as rain and temperature, hybrid architectures have emerged that build the temporary forecast coding the spatial pattern of the neighborhood.
In [7], Shi et al. formulate precipitation nowcasting as a spatio-temporal sequence forecasting problem in which both the input and the prediction target are spatio-temporal sequences. They extend the fully connected LSTM (FC-LSTM) to have convolutional structures in both the input-to-state and state-to-state transitions, they propose the convolutional LSTM (ConvLSTM) and use it to build an end-to-end trainable model for the precipitation nowcasting problem. Experiments show that the ConvLSTM network captures spatio-temporal correlations better and consistently outperforms FC-LSTM and the state-of-the-art operational ROVER algorithm for precipitation nowcasting.
In [8], Souto et al. use a ConvLSTM architecture as a spatio-temporal ensemble approach. The channels in the convolution operator are used to input different physical weather models. In this way the ConvLSTM encodes the spatial information which are subsequently learned by the recurrent structures of the network. The results show that ConvLSTM achieves superior improvements when compared to traditionally used ensemble techniq ues such as BMA [9].
As a matter of fact, there are a plethora of opportunities to be investigated extending the initial results we have achieved in adopting Deep Neural networks to weather prediction. Linear and causal convolution operators (the latter also known as temporal convolution), for instance, have resulted in deep networks architectures that use convolutions to encode and decode time and space with greater precision. Raissi and colleagues [10] investigate the integration of physical laws described as a set of partial differential equations to the training process. By means of such integration, the training process is bound to obey the physical laws, an approach that has been dubbed as model teaching . Another area of interest is multimodal machine learning (MML) [11]. In MML, data from different representations are complementarily used in building models, including: images; textual data; quantitative dataetc... This can be extremely interesting in weather forecast as more data is captured from satellite images and sensors data to weather bulletins and predictive physical models.
REFERENCES
1. Amy McGovern, Kimberly L. Elmore, David John Gagne II, Sue Ellen Haupt, Christopher D. Karstens, Ryan Lagerquist, Travis Smith, and John K. Williams. Using Artificial Intelligence to Improve Real-Time Decision-Making for High-Impact Weather. AMS. 2017
2. Qi Fu, Dan Niu, Zengliang Zang, Junhao Huang, and Li Diao. Multi-Stations’ Weather Prediction Based on Hybrid Model Using 1D CNN and Bi-LSTM. Chinese Control Conference (CCC), 3771-3775. 2019
3. Anthony Wimmers, Christopher VThomas Bolton and Laure Zanna . Applications of Deep Learning to Ocean Data Inference and Subgrid Parameterization. Journal of Advances in Modeling Earth Systems 11:1, 376-399. 2019
4. Anthony Wimmers and Christopher Velden , and Joshua H. Cossuth . Using Deep Learning to Estimate Tropical Cyclone Intensity from Satellite Passive Microwave Imagery. Monthly Weather Review 147:6, 2261-2282. 2019
5. S. Scher. Toward Data-Driven Weather and Climate Forecasting: Approximating a Simple General Circulation Model With Deep Learning. Geophysical Research Letters 45:22, 12,616-12,622. 2018
6. Brian S. Freeman, Graham Taylor, Bahram Gharabaghi and Jesse Thé. Forecasting air quality time series using deep learning. Journal of the Air & Waste Management Association, Volume 08, Issue 8 , Pages 866-886, 2018
7. Xingjian Shi, Zhourong Chen, and Hao Wang. Convolutional LSTM Network : A Machine Learning Approach for Precipitation Nowcasting. arXiv, pages 1–11, 2015.
8. Yania Molina Souto, Fábio Porto , Ana Maria de Carvalho Moura , Eduardo Bezerra : A Spatiotemporal Ensemble Approach to Rainfall Forecasting. IJCNN , pages 1-8. 2018
9. Raftery, A. E., Gneiting, T., Balabdaoui, F., and Polakowski, M.: Using Bayesian model averaging to calibrate forecast ensembles, Mon. Weather Rev., 133, 1155–1174, 2005.
10.Raissi, M., Predikaris, P., Karniadakis, G.E., Physics-informed neural network: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations. Journal of Computational Physics, 378, pp.686-707, 2019.
11.Tadas Baltrusaitis, Chaitanya Ahuja, and Louis-Philippe Morency, MultiModal Machine Learning: A Survey and Taxonomy, https://arxiv.org/pdf/1705.09406.pdf
Researchers today are generating volume of data from simulations, instruments and observations at accelerating rates, resulting in extreme challenges in data management and computation. In addition to publications, scientists now produce a vast array of research products such as data, code, algorithms and a diversity of software tools. However, scholarly publications today are still mostly disconnected from the underlying data and code used to produce the published results and findings, which need to be shared. This presentation will discuss a funded project to acquire and operate an extensible Data Lifecycle instrument (DaLI) for management and sharing of data from instruments and observations that will enable researchers to (i) acquire, transfer, process, and store data from experiments and observations in a unified workflow, (ii) manage data collections over their entire life cycle, and (iii) share and publish data. This presentation will also discuss our approach in generating and sharing data and artifacts associated with research publications, and therefore, providing access to a platform that makes data findable, accessible, interoperable, reusable and reproducible.
Users of floating-point arithmetic (floats) have long experienced the disconnect between mathematically correct answers and what a computer provides. Choices made in the 1986 IEEE 754 Standard for floats lead to irreproducible results that destroy the confidence we experience, say, when working with integers. After 33 years, language support for mandated internal flags (rounding, overflow, etc.) remains nil, so float hazards are almost invisible. The Standard does not require correct or consistent rounding of transcendental functions, so bitwise portability of float-based programs is nonexistent.
The emerging posit standard is a fresh approach to computing with real numbers that is fast, bitwise-reproducible, and capable of preserving mathematical properties like the associative and distributive laws of algebra without sacrificing performance. Complete hardware-software stacks supporting this new kind of arithmetic are beginning to appear, so we now have the hope of eliminating IEEE 754 "weapons of math destruction" with something much closer to the logical behavior we expect from computers.
File attached
EOS is the storage system of choice for CERN's data storage and
is used by various WLCG Tier1 and Tier2 facilities, including at the CHPC.
EOS is an elastic, adaptable, and scalable software based solution for
central data recording, user analysis and data processing.
It has a multitude of supported protocols and authentication methods.
We will present what EOS is, what is does, and how we use EOS in
conjunction with our Tier 2 facility, and how EOS is used in a couple of
other examples.
The Control and Monitoring (CAM) Team at the South African Radio Astronomy Observatory (SARAO) is responsible for implementing software solutions for the collection of sensor data from all of the components, user-supplied equipment and ancillary devices that make up the 64-dish MeerKAT Radio Telescope. Recently, the CAM Team developed and deployed a new solution called KatStore64 which provides services to the MeerKAT Telescope Operators, Astronomers and academia to access the telescope’s sensor data.
In order to capture, store and consume all of this data, the CAM Team makes use of the services offered by the Centre for High Performance Computing (CHPC) for long term storage of the data and employs APIs to extract and present the stored data to users.
My poster/talk will illustrate how the CAM Team has built and implemented the KatStore64 service for the storage and retrieval of sensor data for the MeerKAT Radio Telescope.
Ilifu is an Infrastructure as a Service cloud that utilises OpenStack to provide its core services. It is run by a consortium of South African universities and provides data intensive computing resources to Astronomy and Bioinformatics users. This talk describes how we are utilising federated identity services enable the use of ilifu by users in a way that can be managed by individual project groups without needing to contact ilifu support to have them create or remove accounts. It will explain how this has been done using tools run by EGI, and using tools integrated locally.
First-principles simulation has become a reliable tool for the prediction of structures, chemical mechanisms, and reaction energetics for the fundamental steps in homogeneous and heterogeneous catalysis. Details of reaction coordinates for competing pathways can be elucidated to provide the fundamental understanding of observed catalytic activity, selectivity, and specificity. Such predictive capability raises the possibility for computational discovery and design of new catalysts with enhanced properties.
In the case of mesoporous materials like zeolites, the well-defined pore structures and adjustable reactivity centers in the pore walls allow for efficient control of the catalytic properties. In addition to the reactivity at the catalytic center, the mobility of the reaction components throughout the network structure is crucial to the design. In this contribution we will use GPU-accelerated molecular dynamics simulations to study the diffusion of small molecules through zeolite structures.
Kenneth Allen - Greenplan Consultants - kennethguyallen@greenplan.co.za
Greenplan Consultants undertook a combined smoke, ventilation and wind study for a basement/underground parking area of approximately 27 000 m$^2$. This presentation gives an overview of the project and the experience of running it at the CHPC. In order to reduce the size of the transient model, the full domain (about 0.25 km$^3$) was modelled under steady-state conditions using OpenFoam. The wind flow patterns around the basement were then imposed as boundaries on the transient model of the basement. Even with this approach, the transient model was too large to simulate on a small office network, so high performance computing (HPC) was essential.
Fire Dynamics Simulator (FDS) 6.7.0. was used for the transient simulations. It is purpose-written for simulating fire and smoke, and uses the computationally intensive Large Eddy Simulation (LES) method. The FDS model CHPC requirements were as follows - RAM: ≈ 100 GB; Nodes used: 10-15; Cores used: 240-360; Simulated time per case: ≈ 1-2 min; Wall time per case: ≈ 20-60 hours; Total cells: max. 70-80 million; Cell size: 100 mm; Data output per simulation: 200-250 GB.
FDS can make use of OpenMP (Multi-Processing) and MPI (Message Passing Interface). Tests on the CHPC with OpenMP enabled showed little-to-no improvement, so OpenMP was set to 1 (disabled). An experiment was made whereby all cores per node were booked on PBS but only half were used to run MPI process. This did not give better performance – possibly because of ghost processes running on one or two of the cores. Subsequently, all models were run with 1 MPI process per core, with 24 MPI processes per node. This seemed to be the best option for cost-effective performance.
FDS makes use of manually-specified rectilinear meshes. Unfortunately, where parallel simulation is desired, each MPI process requires at least one mesh, which means the mesh domain must be manually split up into sub-meshes. Any mismatch in mesh size leads to uneven loading on the cores, which means that the less heavily loaded cores have to wait. Due to the rectilinear grid, there are also “wasted” cells in walls/floors/roofs which have no function but contribute to the computational load. Thus, although the initial CSIR scaling tests on the CHPC (6 million cells) were promising for cell counts as low as 30 000 cells per core, scaling tended to be less efficient than expected.
On a number of occasions the simulations progressed at different speeds despite having the same configuration, flow speeds, and boundary conditions. It is possible that this might have been caused by ghost processes on individual cores and the CHPC architecture effect – in particular, the blocking ratio between racks. As an experiment on our final model geometry, we reduced the number of nodes in use from 15 (360 cores) to 10 (240 cores). The cell count per core was a factor of 2.5 higher, the area modelled was larger, and there were more jet fans and extraction fans than in the previous model. Despite this, the CHPC wall time required per unit simulated time increased by a factor of only 2. Rigorous testing is necessary before any conclusions are drawn, as a rough test like this does not provide sufficient data and there might be factors not taken into account. While the above meant that simulations did not run as fast as desired, they ran far faster than they would have on a small office network (it would have taken years, if they ran at all). Greenplan had a good experience with the CHPC and are keen to use it for future projects of this nature.
Enzymes which are directly bound to metal cofactors are referred to as Metalloenzymes. These enzymes play various biologically important roles from catalyzing electron transfer reactions to being important structural components of protein structures. Due to the abundance of metal containing enzymes and the role they play in important biological processes, it is important to study these enzymes. In-sillico approaches are readily used to study protein structure and Molecular Mechanics (MM) is an essential tool used for understanding protein dynamics. MM is used to describe protein behavior by applying a MM force field to describe bonded and nonbonded terms of a protein structure. The accuracy of the force field in describing a particular protein structure is highly dependent on the force field parameters. Unfortunately, for metalloenzymes there are no currently available force fields which can accurately describe the coordination environment of metals in metaloenzymes. As a result, performing an accurate Molecular Dynamics (MD) for metalloenzymes is extremely challenging using available force fields. To overcome this limitation Quantum Mechanics (QM) may be applied to elucidate the parameters required for accurate description of metalloenzymes during MD simulations. This approach involves the use of potential energy surface (PES) scans to evaluate the angles, bonds and dihedral parameters that are important to describe the metal binding site. Experimentally derived energy profiles generated from PES scans are then fitted using least squares fitting to a theoretical force field to generate the force field parameters. This approach three cases of metal coordinating enzymes. The first are the Auxilliary Activity family 9 (AA9) enzymes which are Cu(II) containing enzymes that have been shown to increase the rate of cellulose degradation. Secondly, new parameters were also used in the identification of novel inhibitory compounds against the Mn(II) coordinating HIV-1 reverse transcriptase enzyme. Finally, this approach was applied to the Zn(II) Bi metallic active site center of Beta lactamase enzymes which are contributors to the development of bacterial antibiotic resistance. For all three cases force field parameters were successfully generated and validated using MD simulations
The sugarcane industry is an important agricultural activity in South Africa generating an annual estimated average direct income of R14 billion. Economic loss due to Eldana saccharina (eldana), a lepidopteran stem-borer, is estimated to be R1 billion per annum. Commercial sugarcane cultivars (Saccharum spp. hybrids), have different susceptibility ratings to eldana, varying from low to high risk of sustaining economically damaging infestations. The South African Sugarcane Research Institute has utilised the resources of the Centre for High Performance Computing in an approach involving high-throughput RNA sequencing (RNA-seq) to identify early and late response genes that are differentially expressed in two sugarcane cultivars possessing contrasting resistance phenotypes when challenged with eldana herbivory. The results will be used to identify molecular mechanisms involved in the successful defence response and identify candidate genes which are most likely to be useful in breeding for resistance to eldana.
HPC content:
Annotation and assembly is a computationally intensive process that requires considerable CPU time and effort. Various bioinformatic tools were used for the de novo transcriptome assembly and the differential expression analyses required in this project.
Datasets of ever increasing size and complexity are being generated in the biomedical field to answer questions about human and animal health. Data on human health have to be managed responsibly to ensure protection of participants in health studies. Additionally, many governments are clamping down on the transfer of datasets out of country borders. In order to respect these concerns while still facilitating ethical and responsible data sharing for analysis, new policies and infrastructure need to be developed. There are several initiatives working in this space, including the Global Alliance for Genomics and Health (GA4GH), which is building standards and tools for sharing of genomic data globally. A new EU funded research project, CINECA (Common Infrastructure for National Cohorts in Europe, Canada, and Africa), is developing infrastructure to implement GA4GH standards to enable the analysis of data across cohorts without the requirement for the transfer of large datasets to third parties. This includes development of security systems for authentication and authorization of researchers, harmonization of data across heterogenous studies, and development of cloud-based tools for federated data analysis within the confines of participant consent. This presentation will describe some of the standards and tools being developed and implemented in the CINECA project.
The 3rd Industrial revolution of the 20th Century ushered in the 1st Information Revolution that brought the internet, digitisation, digitilisation and digital transformation and created a basis for knowledge-based economies. It is now widely accepted that the world is experiencing the advent of the 2nd Information revolution that is ushering in a 4th Industrial Revolution - a revolution that is characterised by a fusion of technologies to address current and future human needs. The 4th Industrial revolution is also characterised by large amounts and variety of data – coming from various sources at high frequency – and our ability to analyse them, in real-time and derive information and knowledge for timely decision making. It is anticipated that the 4th Industrial revolution will revolutionise Industry production processes through advanced automation (often referred to Industry 4.0), it also further anticipated that it will revolutionise practice and effectiveness in a variety of areas - health care provision (e.g. personalised medicine), development of Smart Cities , precision agriculture and help address weather and climate change.
There is therefore need for African countries and developing countries to respond to the onset on the 4th Industrial revolution (amidst arguably addressing challenges from previous industrial revolutions still unravelling in the continent) . This will help to bridge the digital divide and help not leave anyone behind – and achieve Africa’s vision 2063 – the Africa We Want. It will also help accelerate attainment of Sustainable Development goals through riding on technology advances, efficiency and transparency. There is need for Africa to transform its infrastructure, research & innovation ecosystems, skills and education systems etc – this for 4th Industrial revolution readiness and competitiveness of African economies and Africans in this new dispensation. Africa and African countries need to have tailor made responses to the 4th Industrial revolution and its implications to the African context. This can be done by concretising National, Regional and Continental Policy Frameworks, structures, resourced roadmaps and increased expenditure in Research, Science, Technology and Innovation and developing partnerships . The universities and other centers of knowledge creation and skills development must play a critical role. The Universities must be alive to this responsibility and aim to transform to be a research-intensive institutions – and is enhance their internal university innovation ecosystems including around data exploitation through innovations.
This talk will provide an update on the developments of around data in Botswana, this from the prism of policy and strategy development, research and Innovation, skills development and science communication for public and policy engagement – this to help address Botswana’s socio-economic challenges and attainment of Vision 2036 – Prosperity for all and address 4IR preparedness. The talk will discuss developments around Botswana Open Data Open Science, Botswana Space Science and Technology Strategy Development, highlight example National Open Data projects and discuss the University Industry Government Co-creation Initiative that aims to foster innovation- including around exploitation of open data.
INTRODUCTION
Given the complex relationship between eResearch stakeholders within universities and research organisations, a “one size fits all” solution to the development of a national eResearch support service is not practical. Services contributed by Libraries, IT and research administrations are at different stages of maturity, and the South African landscape is characterised by scarce skills in areas of software and systems support. To advance national eResearch capability, a considered approach requires both costly infrastructure investment and collaborative support services.
BACKGROUND
The emergence of a new paradigm, “sometimes called eResearch”, gave rise to the examination of a national information service framework in 2005.( ) The need for joint action was identified to meet the challenges of eResearch cost-effectively in South Africa. A specialized agency was proposed to provide support services, with a governance model that should work well for all participants. Two reports commissioned by the Department of Science and Technology assisted in conceptualising strategic plans for the further development of South Africa’s research infrastructure, including the cyberinfrastructure component. The recommendation to establish of a National Integrated Cyberinfastructure System (NICIS) was accepted and plans for follow-up activities approved in 2013. NICIS comprises several core components of the Tier 1 infrastructure: a national Center for High Performance Computing (CHPC), the South African Research Network (SANReN), and the more recently established Data Intensive Research Initiative for South Africa (DIRISA). Experience of the Research Data Management project component of the DIRISA Tier 2 ilifu infrastructure has provided valuable lessons the collaborative development of shared services that can now be evolved to the wider community.
FROM INFRASTRUCTURE DEVELOPMENT TO SERVICE ORIENTATION
As research becomes more multidisciplinary, more collaborative and more global, researchers seek to leverage the South African investment in specialist scientific equipment and domain-specific infrastructures, often generating massive data outputs for analysis in international collaboration. As the national research infrastructure moves from an experimental testbed to a user-oriented environment, a challenge faced by most eResearch infrastructures is the provisioning of sustainable services, and the monitoring of user experience (UX), to improve the interaction of researchers with the infrastructure. This critical component is seldom defined explicitly in the infrastructure development, and the research community have little interest in the expansion of cost-effective services beyond their own needs, and especially beyond the duration of their funded project. Responsibility at present, falls to the host entity to realise the full potential of the national cyberinfrastructure, and the collaboration enabled with global infrastructures. A limited science system suggests a federation of distributed support services, including multiple universities and institutional partners to meet the ever-increasing need to meet both current user support and ongoing data access.
A pilot project to support a South African eResearch support service will build on the eResearch Africa conference hosted bi-annually at the University of Cape Town since the initial event in 2013. An annual training workshop aimed at professional development and career enhancement opportunities recognizes the varied job roles associated with eResearch. Institutional eResearch capacity building will focus on selected teams of information professionals through sponsored participation in designated training programmes and national events.
CONCLUSIONS
The development of a national support service model is intended to improve distributed efficiency, rather than to centrally consolidate a limited pool of existing human resources. The effect of overextending the existing capacity poses serious threat to the realisation of the national cyberinfrastructure, with discussion of actual use cases in this presentation.
Due to the complex relationship between eResearch stakeholders within institutions, a “one size fits all” solution is impractical, and a phased approach is recommended, leveraging a brokerage model to access third party services and avoid scenarios where services are developed and implemented and then subsequently “orphaned” by lack of support and changing financial priorities.
The potential administrative overhead of service development projects, established by individual service level agreements with multiple institutions, warrants further consultation on the project governance with university executives, senior researchers and infrastructure managers.
Capability approaches to advanced computing technologies must address more than the big shiny stuff. A considered approach requires both costly infrastructure investment and collaborative support services. The user experience of researchers, and their improved interaction with the national cyberinfrastructure should ultimately direct the project and its evaluation.
In a world where more and more people are connected every day, new systems pop up and
access can be gained from any device anywhere, we need to ask if the data that we are working
on (viewing, editing and manipulating) is original and safe? The value of data as an asset is
increasing as well as the potential threat in its transformative and informative power. The concept
and roll out of Institutional Repositories (IR) and Institutional Data Repositories (IDR) is fairly
mainstream in South Africa, hosting large valuable and often invaluable sets of data. In a
connected world, cyber threats are real and have to date caused harm to many organisations. Is
our data really safe and trustworthy in South Africa? South Africa has seen a dramatic increase
in the amount of cyber-attacks in 2019, with as much as a 22% increase in malware attacks
compared to 2018 alone. Malware attacks only form part of an array of cyber threats that are
carried out on a daily basis. In short, the answer is that no system is 100% safe against cyber
attacks, there are however systems and processes in place to increase and safeguard our data.
Today’s cybercriminal strategies target every link in the attack chain to gain access to resources
and data, exploiting them relentlessly. Holding data for ransom, modifying data, defacing of data
and selling of data are some of the perils that more and more organisations are facing when
breached. The key to safeguarding data is to ensure that policies, systems and procedures are
put in place to deal with the various links in the attack chain. This presentation will focus on what
is happening on an international and national level with regards to cyber security threats and how
it affects our research data. The presentation will also highlight the attack chain and what can be
done at the various linkages to make systems and organizations more secure.
At the North-West University (NWU) interest in incorporating computational chemistry in training and research started in the late 1990. Although there was not much support for this interest in computational chemistry, the need for understanding the chemistry in especially catalysis was identified.
Starting with old discarded computers and the cheapest possible software, the first attempts were made in calculating structures of transition metal complexes used in catalysis research at NWU. Due to the limitation of the resources, only gas phase reactions in homogeneous catalysis could be investigated. As the value of the computational investigations became evident, more resources were acquired.
It was however only in 2002 that support from the Research Focus Area (previously called Separation Technology) at NWU was obtained. Formal training of one staff member and the establishment of a dedicated Laboratory for Applied Molecular Modelling was funded. After careful evaluation of the needs in the research and the abilities of the researchers, it was decided to invest in Accelrys Materials Studio (for research) and Spartan (for training) software. At the same time 10 workstations and a 12 CPU cluster were acquired.
Although this was a major step forward, catalysis research was still limited to gas phase reactions in homogeneous catalysis investigations, with transition state calculations being a challenge. At this stage the CHPC was established. After a short phase of development and streamlining operations and software at CHPC, access to these resources were obtained by NWU researchers.
With the access to CHPC resources, limitations to the type of investigations gradually disappeared. The homogeneous catalysis investigations could be expanded to real system investigation, including solvents. Models could be expanded from explanations of observations to prediction for activity. Heterogeneous catalysis could also be included in research.
Now, computational catalysis research at NWU was ready to investigate real problems and try to find solutions. One such real problem being investigated at NWU is the development of new/alternative catalysts to apply in the generation of alternative and renewable energy.
Speech-enabled human-machine interfaces are becoming increasingly prevalent. There is, however, a disparity between the languages these systems are available in and the languages spoken in South Africa. This is because a tremendous effort is required to collect and refine large speech corpora. For the majority of South Africa’s languages, very little speech data is available. This creates a challenge due to the “data hungriness” of automatic speech analysis techniques, specifically those which yield the best performance such as deep learning. Once sufficient initial resources exist, automatic data harvesting strategies can be used to further increase the amount of available data in under-resourced languages. The aim of the work we report on is to improve existing ASR systems for the 11 official languages of the country. These systems are currently based on the recordings of the NCHLT (National Centre for Human Language Technology) corpus, which consists of an estimated 55 hours of speech obtained from 200 speakers for each language. During the NCHLT project additional speech data was collected but not released. To determine whether this additional data is useful, acoustic evaluation of the audio is required to detect both low signal-to-noise ratios (SNRs) and transcription errors. The decoding process with state-of-the-art Deep Neural Network-based models is more than an order of magnitude slower than real time on CHPC’s Lengau Dell cluster’s processors. It requires more than 10 CPU hours to process one hour of audio data. We therefore used CHPC to run the jobs required for processing one language in parallel. This allowed for approximately 200 hours of auxiliary data to be processed and used less than 50 GB of memory. The harvested data from this process was subsequently used to train factorized time-delay neural networks (TDNN-F). This model architecture was recently shown to yield good results in resource constrained scenarios (less than 100 hours of speech). These models significantly reduced phone error rates for the 11 languages. Each TDNN-F model trained in about 8-12 hours on CHPC's Lengau GPU cluster.
Lithium Sulphur batteries suffers from the low conductivity of S and the solubility of intermediary polysulfide species during cycling. It has been reported that Se and mixed SexSy represent an attractive new class of cathode materials with promising electrochemical performance in reactions with both Li ions. Notably, unlike existing Li/S batteries that only operate at high temperature, these new Se and Li/SexSy electrodes are capable of room temperature cycling. To study large systems and impact of temperature effectively, empirical interatomic potentials of Li2S were derived and validated against available experimental structure and elastic properties. Complex high temperature transformations and melting of Li2S was reproduced, as deuced from molecular dynamics simulations. Li2S was found to withstand high temperatures, up to 1250K each which is a desirable in future advanced battery technologies. Cluster expansion and Monte-Carlo simulations were employed to determine phase changes and high temperature properties of mixed Li2S-Se. The former generated 42 new stable multi-component Li2S-Se structures. Monte Carlo simulations produced thermodynamic properties of Li2S-Se system for the entire range of Se concentrations obtained from cluster expansion and it demonstrated that Li2S-Se is a phase separating system at 0K but changes to mixed system at approximately 350K.
Granular materials are used in several industrial applications. One example of such an industrial application is rotary kilns, often used for drying, pre-heating and the reduction of a moving, high-temperature granular bed. The granular flow in these reactors have an important influence on capacity, product quality, and economic feasibility. Rotary kilns, in the pyrometallurgical industry, often have diameters up to 6m, with lengths in excess of 80m, and operating at temperatures of 1000 to 1400°C. Because of the size of these kilns, modelling the granular flow using the discrete element method (DEM) would result in excessively high computational costs. In this work, we therefore made use of a continuum approach to describe the granular flow.
We adopted the μ(I) dense granular flow model proposed by de Cruz et al. (2005) and later extended by Jop et al. (2006). This model is a rate-dependent, phenomenological description of dense granular materials and can be characterised as an elsto-viscoplastic material description with a frictional yield criteria. The flow model approximates an effective friction coefficient through a relationship between plastic flow strain rates and a confinement time scale to account for the internal, inter-particulate motion.
We implemented the material model into OpenFOAM, an open source, finite volume (FV) based, partial differential equation toolkit. The volume of fluid (VoF) method was used to capture the discrete granular-fluid interface, enabling the simulation of large granular bed deformations. The numerical scheme was stabilised by using pressure and viscosity regularisation, along with a semi-implicit coupling between the internal pressure and velocity fields.
In our project we were faced with serious technical and computational challenges involving combustion, heat transfer, fluid flow, high-temperature chemistry, and the movement of a large granular bed. Our FV approach enabled us to make valuable computational modelling and simulation contributions to the development of a new high-temperature process technology.
Seven decades of HPC has been empowered by the abstraction of “the von Neumann Architecture” and its many derivatives, driven to a significant degree by Moore’s Law and the exponential growth of device density and concomitant clock rates yielding a performance gain over that period of more than ten trillion for floating point computation. But a perfect storm of recent technology trends has terminated this unprecedented expansion and challenges the future opportunities beyond exascale computing. But even as the end of conventional processing practices is flat-lining, a new world of non von Neumann execution models and architectures is emerging igniting a revolution for the next generations of computing systems orders of magnitude greater performance than is currently achieved. Even more important is that the reality of HPC users is that approximately 90% of the Top-500 machines measured with the HPL benchmark demonstrate only about 1% of the performance of the fastest machines. Thus we are much further away from exascale than is generally assumed and therefore much greater gains are required to truly bring the major base of HPC users into the exascale era. New non von Neumann architectures and models, such as Quantum Computing, Neomorphic Computing, and Continuum Computing (this last presented at CHPC18) are offering important possibilities for the future. Earlier non von Neumann techniques previously explored in past decades, such as static and dynamic dataflow, cellular automata, systolic arrays, and special purpose designs may also serve as starting points for new classes of useful computing methods even as Moore’s Law recedes. Finally, advanced technologies beyond conventional semiconductors such as cryogenic such as single flux quantum logic provides yet another dimension of potential post exascale strategies. This Keynote Address will convey a fast paced odyssey through the near future opportunities of HPC non von Neumann based computers. Questions will be encouraged by participants throughout the presentation as well as the Q&A session at its conclusion.
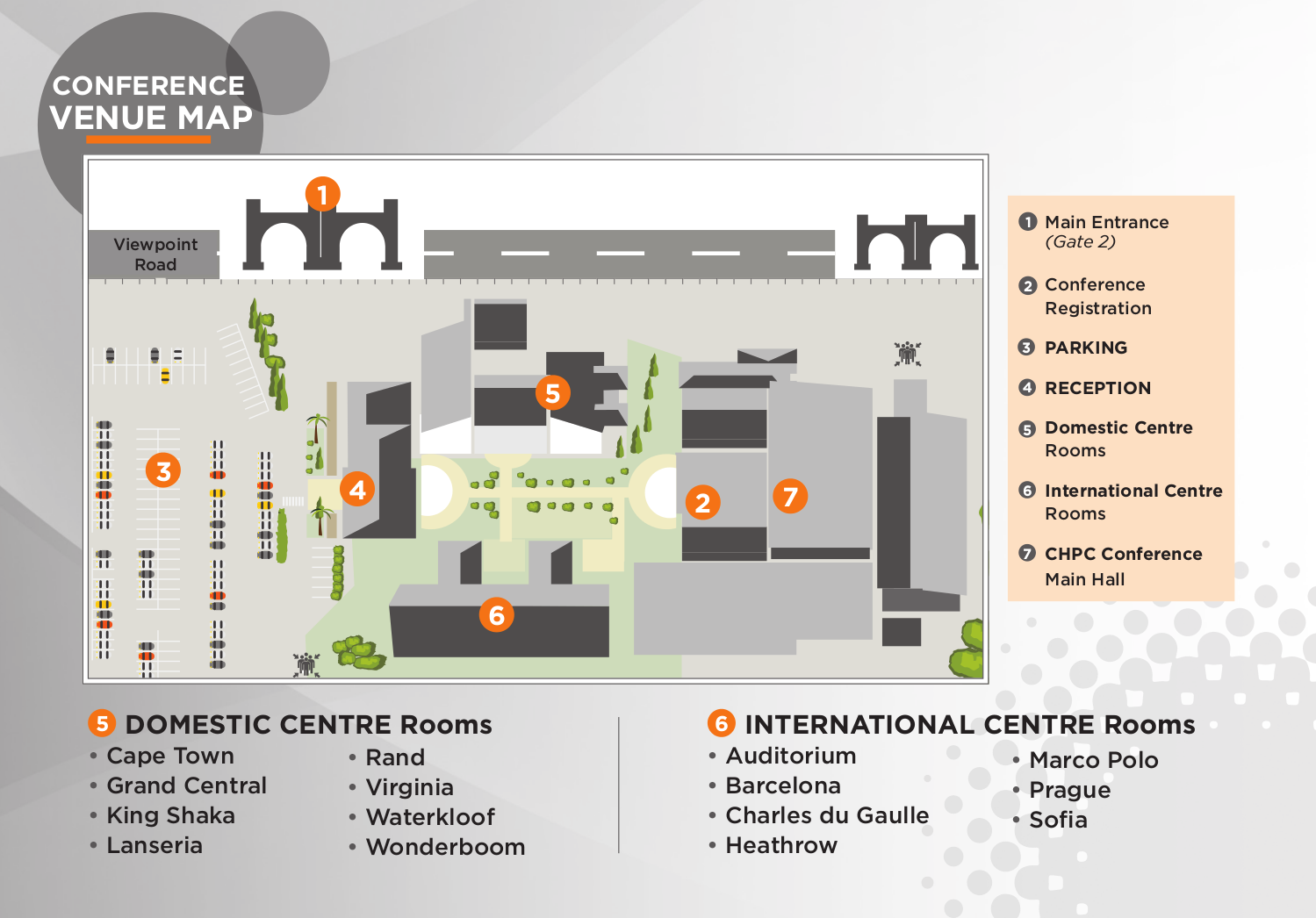{kind=link}